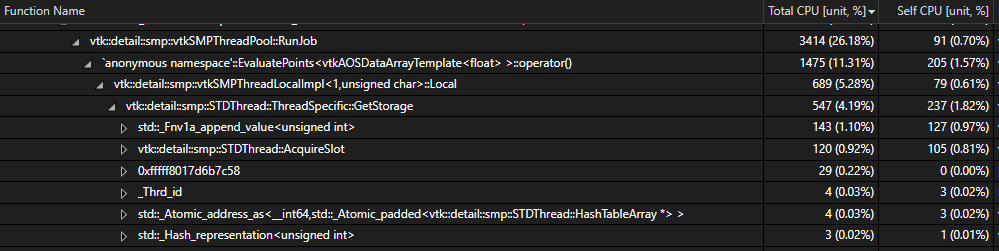
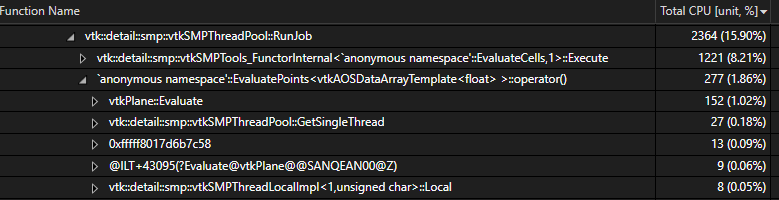
I’m attempting to generate a bunch of slices from a single polydata using vtkcutter, but while it does parallelize the operation using the vtkSMP API, it doesn’t produce a significant difference vs. single-threaded performance (setting the SMP backend to sequential). It looks like this is due to repeatedly getting the thread-local storage containers in part of the vtkPolyDataPlaneCutter algorithm.
The initial pipline looks something like:
void createSliceAtX(double x … ) {
// “surf” is an actor which has already been created, and whose data we are slicing
vtkPolyData *surfaceData = vtkPolyData::SafeDownCast(surf->GetMapper()->GetInput());
//create a vtkplane at x location and cut the surface
VTKNEW(vtkPlane, plane);
plane->SetOrigin(x, 0.0, 0.0);
plane->SetNormal(1.0, 0.0, 0.0);
vtkSmartPointer cutter = vtkSmartPointer::New();
cutter->SetInputData(surfaceData);
cutter->SetCutFunction(plane);
cutter->Update();
// … (processing the outputs)
}
And this is where its spending most of its time:
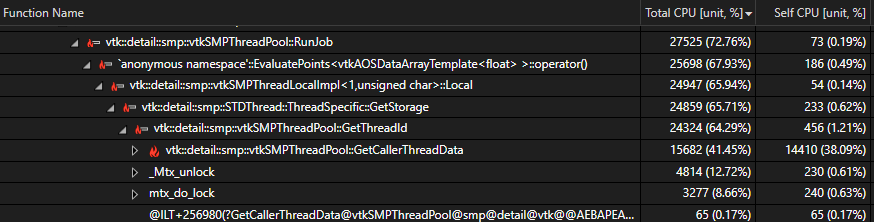
I can validate that this is not a performance artifact because if I set the SMP backend to sequential and thread the “createSliceAtX” function separately I see a roughly ~16x performance improvement (using 16 cores)… however the result is unstable, presumably because vtkCutter on it’s own isn’t thread-safe?
perhaps the thread id can be cached? or replaced with std::this_thread::get_id() which is typically speedy? I took a quick look at the current state on vtk’s gitlab and it doesn’t look like anything has changed recently, but if there’s already a PR or issue for this somewhere please point me toward it!
Happy to provide more info if that would be helpful.
I’m using VTK 9.3.1 compiled with msvc 17 (visual studio 2022) on win 11.