With Timothée Chabat and Francois Mazen, we’re currently working on developing new shaders for the vtkGPUVolumeRayCastMapper class in order to have a more realistic volumetric rendering. We are trying to integrate multiple-scattering effects as well as physically correct shading and shadows. In order to have better rendered details, we are also working on several models to compose volumetric rendering and surface rendering. We have selected four methods and would like to share our results.
Here are the results we obtained with VTK’s current shader:
For each of our methods, we have a coefficient which allows the user to compose between volumetric and surfacic rendering. Here is an image comparing those different methods.
A row corresponds to different results with the same method. In a row, this user-defined coefficient varies from full volumetric (on the left) to almost full surfacic (on the right).
If you want those images with a better resolution or the same comparison on other test scenes, you can find it here : HybridComparison
As one of these methods will maybe be integrated into VTK’s mapper, it is important to us to ask for your opinion on this.
Thanks for your interest and for your opinions !
Gaspard
For these rendering methods a new API will be added for controlling the coefficient of volumetric/surfacic amount. This coefficient does not have any meaning for other volume mappers. We don’t want to add all methods because :
this would add yet another API to the vtkVolumeMapper class that is not supported by all of its subclass
also the volumetric/surfacic parameter does not have the exact same meaning in all methods so the user would need to tweak it according to the chosen method.
We think that it’s not worth it to overwhelme the user with a lot of controls and complicated parameters, and we want to keep it as simple as possible.
Medical folks will know best (like Stephen and friends)
but…could you try generating a better image from the current gpu shader? What you posted looks really specular and I think the gpu mapper can do better than that with the right parameters. Just odd to compare the two when the existing approach looks so off.
The hybrid row looks like it is missing lighting or something, is something off on that row? More contrast, lighting? It looks dark and flat compared to the other rows like it needs more lighting or something.
Hi ! Thanks for your answer !
Yes we can generate better looking images by changing the light’s and material’s parameters. You can find an example below.
The reason we presented those in the post is because we obtained those with equivalent light and material setup as the ones we obtained with the other methods. And as we think we had to correct the physical interpretation of those parameters in VTK’s shader (Phong’s model, normal estimation), it made sense to us to compare them. And in the interpolation method, the column on the right corresponds to the corrected version of VTK’s existing shader.
Your question about the hybrid row is also very relevant. Actually, this method makes a slightly different physical interpretation of some parameters, and a consequence of it is that with equivalent light and material setup, it looks darker.
In those four methods, we use different stochastic estimators and coefficients to blend surfacic and volumetric. It notably depends on the magnitude of the gradient and of a user-defined coefficients. If you’re interested, we’re writing a short paper about it right now, we can share it once it’s done !
Thanks @gthev. Yep, definitely interested in the implementation details.
I asked because just looking at the images in the spreadsheet, it is hard to say that one row is better than the other across the different datasets. For example, if I concentrated on the middle image in each row, the Interpolastic method seems to produce better illumination for the FogRoom dataset whereas the Interpolation method’s illumination seemed better to me for the Cardio one.
This sounds awesome. Really looking forward to more realistic-looking lighting for volume rendering.
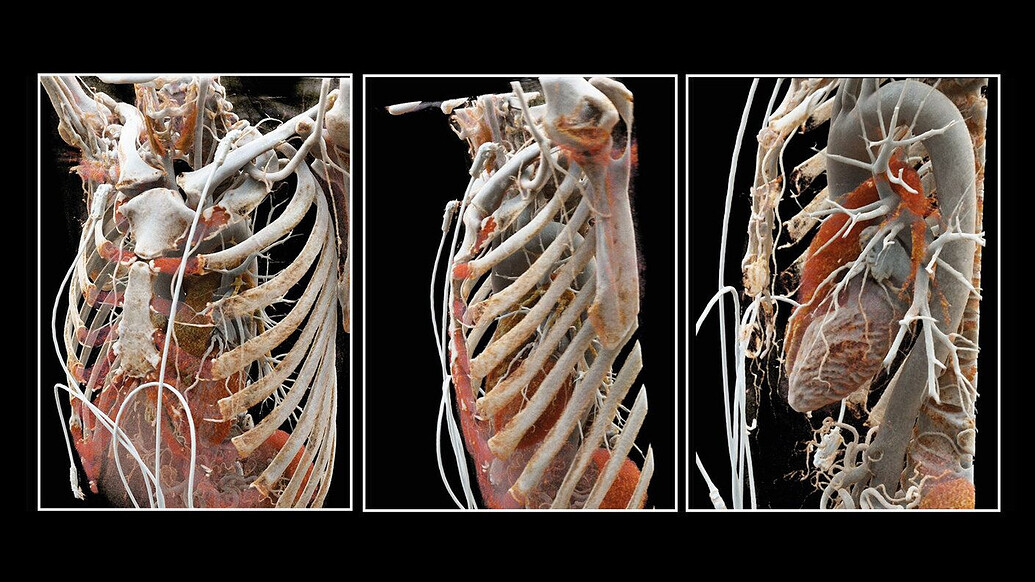
I cannot interpret the images posted at the top. The volume rendering settings do not seem to be set to for visualizing either bones or any soft tissues.
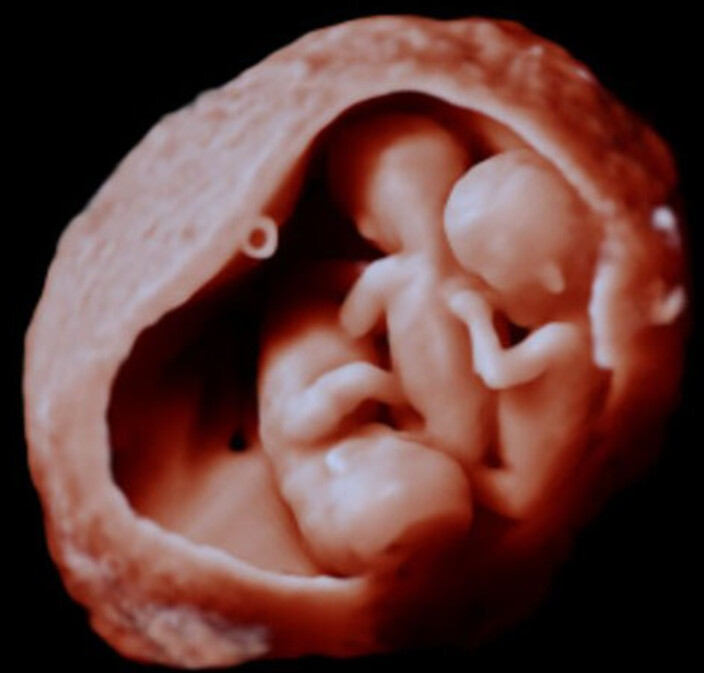
Example rendering results that we would like to get
The 3D cardiac CT image that is rendered above is available here. I can also provide 4D cardiac ultrasound volumes that should be possible to render similarly as the 3D cardiac ultrasound rendering example above.
Potential ideas for improvements
The ideas behind the new illumination methods were not described in this post, and the renderings posted so far are not very informative yet, so I cannot comment on the proposed new methods. instead, I have two suggestions for hugely improving volume rendering appearance, without increasing rendering time, and requiring only small development effort.
Since surfaces and their normal can be estimated directly from 3D volumes, it may be feasible to port these two VTK rendering features that are currently available only for surface rendering:
The volume rendering process is actually the same regardless of the method used to gather the data. What mainly changes is the pre process part ie. the creation of the opacity and color transfer function. We’re not really expert in the medical domain so our results may not be very explicit indeed.
Thanks for the dataset you shared. You can see a rendering of this dataset here , in the “Cardio” tab. The result is a bit less fancy the Blender’s one but the light setup and our transfer functions are mainly to blame here. We would be very interested in additional datasets though
Jiayi has been building upon Gaspard’s and Timothee’s ideas and code. She is investigating other “scattering” methods. They will be less photorealistic than those rendering from Siemens, et al., but her methods target near-real-time rendering on common hardware. She is currently porting them to vtk.js. Thanks for the links to the data, we’ll include them in the demos.
As Timothee stated, a big challenge is the transfer functions…and that isn’t solved by her methods either…
FYI I’m assuming that the folks here are aware of the awesome work that the Scientific Computing Institute at U. of UTAH (i.e., SCI Utah) have done with multidimensional transfer functions. They have some interactive, open source software for interactive creation of transfer functions that you can dig up. Or check out this PhD thesis: MULTIVARIATE TRANSFER FUNCTION DESIGN. There is lots more info available, if anyone needs help I can help connect you to the right people at SCI.
@will.schroeder - that is awesome! Was just talking with @Forrest about the topic of Chapter 4 in that dissertation: “Transfer Function Design Based on User-Selected Samples”. Such an approach would be much more intuitive for medical applications in which certain anatomic features are expected to have a specific appearance. This is the class of methods that we wanted to implement next, after the pseudo-cinematic rendering is in vtk.js.
We have about 30 transfer function in 3D Slicer, used and fine-tuned over many years, for various CT, MRI, US, and PET images: presets in Slicer core. The preset file format is specified here. We have a couple of additional presets in extensions and some of them use custom shading (e.g., distance-dependent coloring).
This is basically equivalent with classifying volume regions and assigning different transfer functions to each region. Classification is not binary, but you apply a mix of transfer functions weighted by the output of the classifiers.
Probably 5-10 years ago it still made sense to try to hand-pick a few metrics (intensity, gradient, occlusion spectrum, etc.) and manually tune their parameters based on user-selected samples, etc., but nowadays it seems more reasonable to use the same deep learning models that are already trained for image segmentation.
Implementing this AI-based volume rendering may not require any new developments: you can save output of each AI-based classifier into a volume and render them using multi-volume rendering. Multi-volume rendering allows you to specify transfer function for each volume.
nowadays it seems more reasonable to use the same deep learning models that are already trained for image segmentation
… sounds like the basis for a research proposal unless it’s already been done. Guided by the prior work from the Slicer community etc. this could be a very impactful and compelling work.