This thread is dedicated to proposing a new design for the VTKHDF format that would describe vtkPartitionedDataSetCollections and vtkMultiBlockDataSets.
The general idea is to have an Assembly group in the file that describes the composite data hierarchy and have its leaf nodes link to top level groups that conform to the existing VTKHDF formats using the symbolic linking mechanisms provided by HDF5 technology (Chapter 4: HDF5 Groups and Links).
Here is a diagram of what it might would look like:
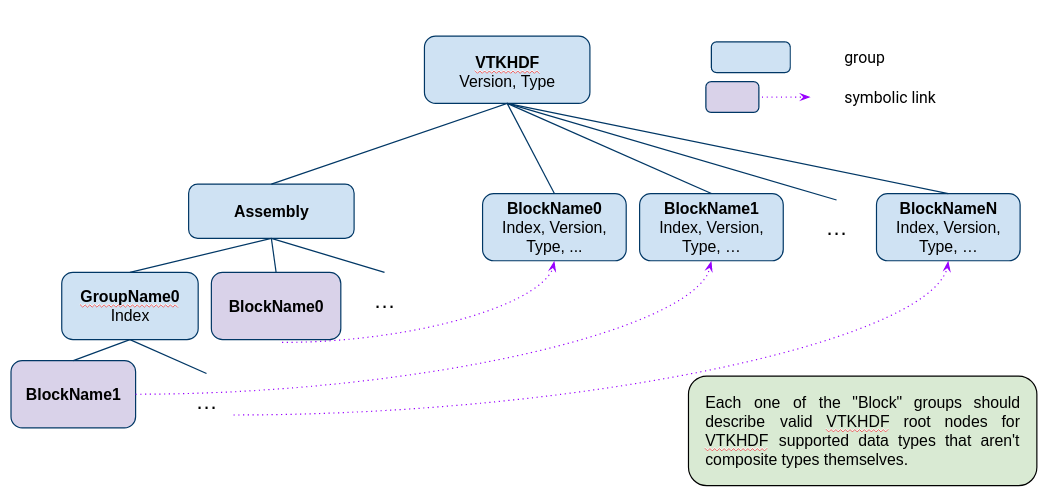
Some details:
- The Index attributes inform the reader of the index of a given block in the flattened composite structure.
- Every leaf in the assembly should describe a non-composite data object to avoid the overhead of recursion while reading the file.
- The assembly structure only needs to be traversed once in the beginning of the reading procedure (and can potentially be read and broadcast only by the main process in a distributed context) to optimize file meta-data reading.
- The block wise reading implementation and composite level implementation can be managed independently from each other.
- It would be feasible for each block to have its own time range and time steps in a transient context with the full composite data set able to collect and expose a combined range and set of time values.
- Reading performance would scale linearly with the number of blocks even in a distributed context.
Does anyone have any input? What are some of the thoughts in the community on the best way to do this?