The Visualization Toolkit (VTK) has relied on an RGB-based image testing framework that uses a patch-based comparison technique. While generally effective, this approach has shown limitations, especially in identifying subtle yet crucial differences between images. A notable issue is the framework’s generous threshold, which was likely set to minimize false positives but has led to overlooking significant differences between test images.
The Current Framework: An Overview
The existing algorithm in VTK’s image testing framework takes an average of a patch from a reference image and compares it against multiple patches in the test image. This patch-shifting technique was designed to accommodate variations in text rendering across different systems. However, the high threshold set to avoid false positives has led to the framework failing to catch glaring differences between images, such as confusing gray with green (see below).


Using Lab Color Space
The Lab color space, short for CIELAB, is designed to be perceptually uniform, meaning that the perceptual difference between colors is consistent across the space. It consists of three channels: L* for lightness, a* for the green-red component, and b* for the blue-yellow component. This makes it well-suited for tasks that require a consistent measure of color differences, such as image quality assessment.
Introducing SSIM and Its Heat Map
What is SSIM?
SSIM (Structural Similarity Index) is generally used for measuring the similarity between two images, often in the fields of image quality assessment, compression, and transmission. It offers a more nuanced approach to image comparison by evaluating the structural integrity of images. It considers three key components: luminance, contrast, and structure. The SSIM index for each patch is calculated using the formula:
SSIM(X,Y) = l(X,Y)^α c(X,Y)^β s(X,Y)^γ
Components of SSIM: Mean, Variance, and Covariance
- Mean: The mean of a patch provides a basic measure of its intensity or brightness. It serves as the baseline for comparison.
- Variance: Variance captures the texture and granularity within the patch. It encodes how pixel values deviate from the mean, providing insights into the patch’s complexity.
- Covariance: Covariance measures the relationship between corresponding patches in the two images. It indicates how much two sets of data change together, capturing the structural relationship between the patches.
The following illustration demonstrates how SSIM would quantify the differences between two sine waves. The luminance aspect is captured by the differences in the means of the two signals. Contrast is influenced by the variations in amplitude between them. Lastly, the structure is primarily determined by the frequency, although amplitude can have a minor effect on it as well.
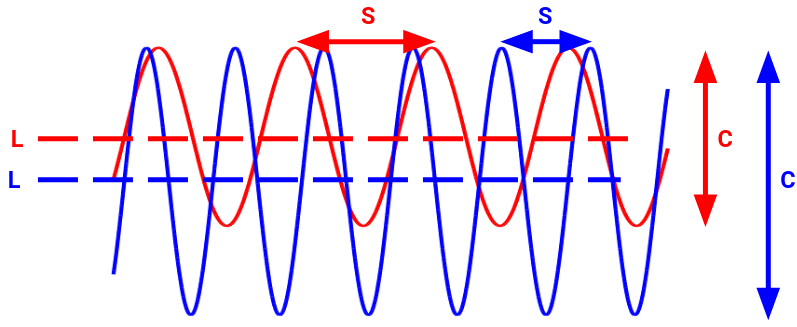
The SSIM’s Output
The term “structural correlation” aptly describes what SSIM measures. It captures how structural components in one image relate to those in the other, making it a more holistic measure of image similarity.
SSIM generates a heat map where each pixel is assigned a value, originally ranging from -1 to 1. For easier interpretation, we propose clamping these values to a range from 0 to 1.
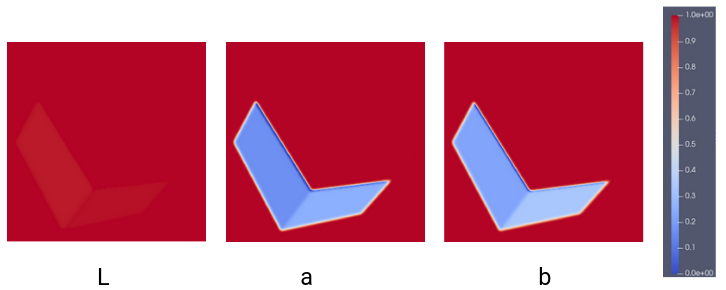
Condensing the SSIM Heat Map to a Single Value
p-Wasserstein Distance
The histograms used in the following are derived from the SSIM heat map. They represent the frequency distribution of SSIM values across the image, providing a statistical view of similarity.
When p=1, the Wasserstein distance is known as the “Earth Mover’s Distance,” which measures the “cost” of transforming one histogram into another. When p=2, it becomes the Euclidean distance between the histograms.
Min Value
Taking the minimum value in the SSIM heat map offers a quick but effective measure of similarity. It penalizes high local discrepancies, regardless of their area.
p-Minkowski Distance
This is a generalization of several distance metrics. When p=2, it reduces to the Euclidean norm. When p=1, it’s known as the “Manhattan distance.”
Challenges and Solutions
Anti-Aliasing
Anti-aliasing, while generally beneficial for rendering high-quality images, introduces a layer of noise and system-dependent variations that can significantly impact the accuracy of image comparison tests. In a testing framework that aims to use a sensitive metric like SSIM, these variations can either lead to false positives or obscure genuine, meaningful differences between images, especially when dealing with wireframes.
To address this, anti-aliasing will be turned off by default in the testing framework. Disabling anti-aliasing will enhance the reproducibility of test results across different systems. More importantly, it will allow us to set a lower, more sensitive default threshold for image comparison, making the framework more responsive to actual changes rather than to artifacts introduced by anti-aliasing. This decision aligns with the goal of improving the framework’s sensitivity and reliability.

Text Rendering
Text rendering has historically posed a challenge in VTK’s image testing framework. The existing patch-shifting technique was designed to handle variations in text rendering across different systems. However, this approach has had the unintended consequence of degrading the accuracy and reliability of the image comparison process, adding complexity and potentially masking genuine differences between images.
The following illustration shows the impact of patch-shifting on a VTK test image that primarily consists of text. Displayed is the difference between the baseline image and the output from our workstation. The text is offset by 2 pixels, and the patch-shifting largely eliminates these discrepancies.
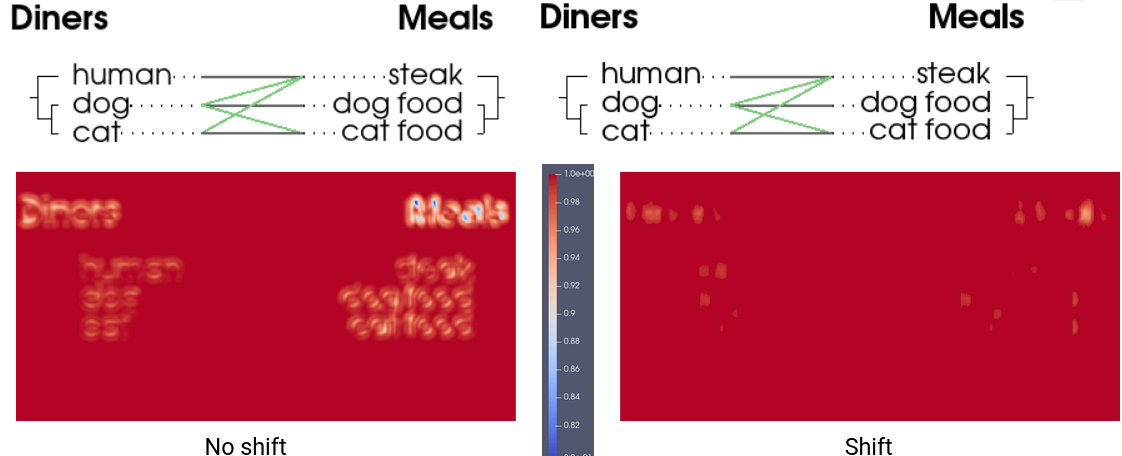
In contrast, the next illustration presents a different VTK test image compared with another image generated on our workstation. This test focuses on an algorithm that carves the letters “VTK” into a sphere. A past change in the algorithm went undetected because the patch-shifting technique effectively blinded us to the alterations.
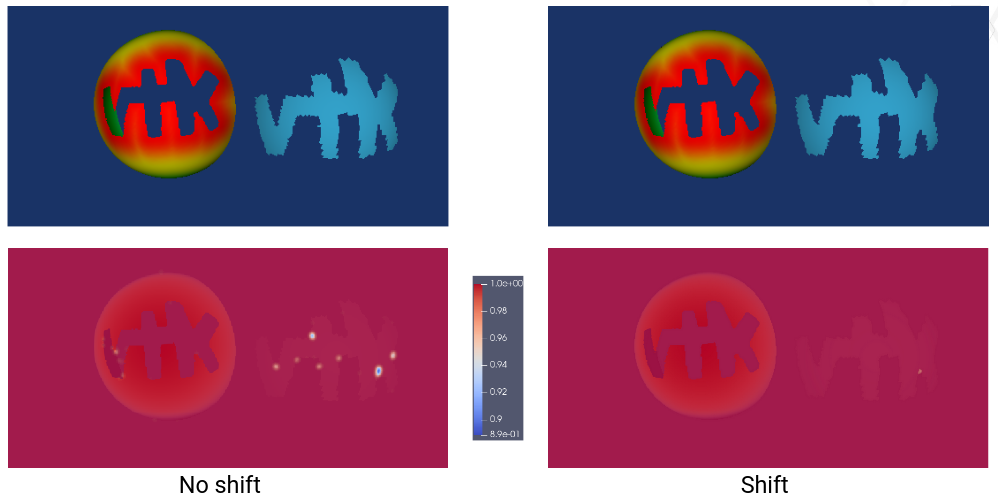
The use of patch-shifting, while initially intended to accommodate minor variations, notably in text rendering, has had the unintended consequence of degrading the effectiveness of our image comparison metrics. As demonstrated, it not only masks small discrepancies but can also make us oblivious to significant changes in the image, undermining the reliability of the testing framework.
One proposition to address this issue in a new SSIM-based framework is to disable text rendering by default for general tests. This would eliminate the need for patch-shifting and could allow for a more straightforward and sensitive default metric for image comparison.
For the specific testing of text rendering, it’s proposed to introduce dedicated tests that use a looser metric. This metric could be designed to accommodate the inherent variability in text rendering, ensuring that text appears as expected without affecting the overall test results for other image components.
To capture what text should be displayed in the general tests, another proposal is to add the text actor’s information as metadata in the outputted PNG images. This would provide a way to verify that the correct text elements are present without having them influence the image comparison metric.
These propositions aim to resolve the challenges introduced by text rendering in image comparison. They offer a potential path to balancing accurate image comparison with effective text rendering testing, although alternative solutions are also welcome.
Baseline Updates
The updates regarding anti-aliasing and text rendering will necessitate updating a large number of baseline images, a step that is unavoidable but essential for long-term accuracy.
Geometric Comparison Tools in VTK
Alongside the proposed changes to the image testing framework, a merge request for geometric comparison tools in VTK has been submitted. These tools offer a more direct and often superior method for assessing algorithmic accuracy by focusing on the underlying data structures and mathematical properties. This approach is particularly advantageous for complex geometries and transformations, where rendering-based tests can introduce additional variables or noise. While not intended to completely replace rendering tests, geometric comparison is frequently a better alternative and serves to complement and enhance the overall integrity of VTK’s testing capabilities.
Conclusion and Open Questions
With the proposed transition to SSIM in Lab channels and the introduction of geometric comparison tools—which are often a better alternative to rendering-based tests—the path is set for a significantly more robust and reliable testing framework in VTK. However, challenges such as text rendering and updating baseline images still need to be addressed. Your insights on these issues, as well as on the utility of the new geometric comparison tools, are invaluable. We welcome all feedback and alternative solutions, especially on the handling of text rendering in the new framework.