Hello, I’m trying to figure out the “on-screen” bounds of an actor.
Right now, I get the actors 3D bounds and transform them into screen coordinates with the vtkCoordinate. The obtained position is somewhat ok. But when rotating the scene, the dimension is very inaccurate and sometimes transforming the bounds gives screen coordinates that are only one pixel apart (when the actor takes up >10 pixels)
Are there any alternatives or what might go wrong for me?
Can you provide more context to what you are trying to achieve?
I’m asking that as the path you are taking might not be the best one. And providing an answer to your question might still fall short compare to your initial goal.
Ok, I guess I figured it out. My goal was to take the 3D bouding box and get a 2D bounding box that encloses the rendered element. The issue was, that I only took the bounds (xMin, xMax, yMin, yMax, zMin, zMax) of the bounding box, transformed the (xMin, yMin, zMin) and (xMax, yMax, zMax) to 2D and thought this should give me the upper left and the bottom right corner.
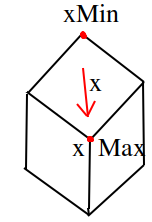
Now the issue is, what if the viewers axis is almost aligned with one of the 3D axes, like here:
Since the user looks in the x direction, xMin and xMax will alsmost give the same 2D coordinate and the resulting 2D bounding box will have approximately the correct height for the rendered object, but it will be very slim.
My solution was the following:
Generate all 8 permutations of the bounds (resulting in (xMin, yMin, zMin), (xMin, yMin, zMax), (xMin, yMax, zMin)…)
Transform all 8 coordinates to 2D
In the 2D coords find the minimum and maximum for x and y. This always gives a 2D bounding box which encloses the object, but sometimes its to large
Shrinking this 2D box to about 60-80% of its size gives good results for my use case