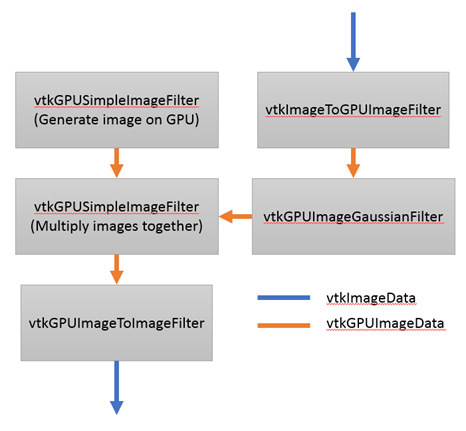
We have several 3D Slicer related projects which require the use of fast multi-pass GPU-based algorithms. vtkOpenGLImageAlgorithmHelper can be used for this, but it requires that the textures are read back into memory as between each pass.
Recently I’ve been implementing several VTK filters to upload vtkImageData to GPU, run any number of GLSL shaders on the textures (as vtkGPUImageData), and then download them back into a vtkImageData.
@ken-martin What do you think? I know there is on-going work in improving low-level support for custom shaders and that is great, but majority of users just interested in having high-level building blocks (filters) to build their processing pipeline. Are you aware of anyone else working on a similar general framework of GPU-accelerated filters? What are the plans for making GPU-accelerated features available for average users (who don’t want to learn GPU programming)?
I know vtk-m (https://gitlab.kitware.com/vtk/vtk-m) has some similar goals but is, optional, a lot larger, and I don’t think they support passing data on GPU from filter to filter yet, but maybe plan to.
Thanks for chiming in. We thought that the VTK community would be excited about the possibility of executing filters on the GPU but from the discussion above it seems that not many people are interested. So, for now, we’ll probably keep prototyping in 3D Slicer. We plan to develop it further and connect it with GPU volume rendering at the next Slicer project week in Boston, if you can come we would be happy to work with you there (or at subsequent project weeks).
In the meantime, if you have some processing implemented in GLSL already, then we can help in getting it working as a filter quite easily.
As @ken-martin said, vtk-m is the project where much of the GPU and many-core processing work is directed. I’m not saying this approach isn’t also a reasonable one, but in terms of community interest, note that vtk-m is the project where that interest is directed for a number of core VTK people. @RobertMaynard may have more to say about that.
What is the status of the GPU integration in ITK? That have some focused effort starting around 2010, but I’m not sure if anyone is still pushing on that.
Some GPU-accelerated filters have been implemented in ITK. A few simple ones for demonstration purposes and a few others for performance-critical processing.
It is good that you brought up ITK, because the approach we proposed above is essentially the same as ITK’s approach, with the difference that for now we do not plan to use OpenCL but only GLSL (for better compatibility and easier deployment). VTK-m is a really nice effort, but it does more what we need and so it is more complex than we would like, and overall it is an entirely different project. VTK almost does everything that we need, so we prefer to just slightly improve it rather than bring in a completely new framework.
I understand that Kitware does not want to divide its attention between vtk-m and other approaches, but I thought there would be more community members who would want to use GPU for data processing without venturing into vtk-m.
So lets start with an understanding what the goals of VTK-m
are:
To have visualization algorithms executed and performant
on exascale HPC machines. For example machine such as Summit,
and the announced Frontier.
Provide developers a single source model, where they can
write small worklets (aka functors) in C++ and have those
compiled and executed using different acceleration languages
such as OpenMP, TBB, and CUDA.
Provide a collection of feature rich parallel primitives
such as those seen in std++17 parallel proposal or Thrust.
We currently have more parallel primitives compare to c++17
but less than Thrust.
Provide a collection of abstractions for common scientific
visualization concepts such as accessing the point of a cell,
point neighborhoods, cell/point locators, and so on.
So as this relates to filters and gpu memory residency.
VTK-m has a design that fully supports keeping data on the GPU as
long as it is needed. The original challenge that we had was that
as VTK and VTK-m use slightly different memory layouts we had to
bring the data back to the host after executing VTK-m algorithms inside
VTK to make sure that downstream VTK filters could access the data.
This data transfer model is alleviated in our new design for VTK-m/VTK
filters that we are currently developing ( https://gitlab.kitware.com/vtk/vtk/merge_requests/5395 ).
In this model we have a VTK-m dataset in VTK and this allows
for memory transfers to be kept between filters. This also will work
with GPU’s that support pageable UVM memory and will allow CPU’s
to access GPU allocated memory without a full copy.
If you have any questions on VTK-m in general please ask
I guess the main problem is that goals of vtk-m seems to be different from ours. We are only interested in running software on commodity multi-core CPU + GPU and prefer a simple solution. It could be less time for us to add a couple of classes to VTK than learning vtk-m’s very generic framework.
If vtk-m could readily fulfill most of our requirements then we could of course reconsider. Our requirements include passing data between filters without copying data to host, rendering filter outputs without copying data to host, easy deployment on a wide range of commodity hardware, have some filters that are important for us - such as surface smoothing and surface to image conversion - implemented on GPU, being able to add new filters without the need to learn a lot about all kinds of architectures that vtk-m supports.
We have support for commodity multi-CPUs through our TBB and OpenMP backend. Currently we only support NVIDIA GPU’s, but will be expanding into other GPU vendors over the next few years.
Yes that is supported between VTK-m filters, and soon will be part of VTK-m aware filters in VTK.
Yes this supported in VTK-m when the accelerator is CUDA. This is done using a double buffer technique due to technical limitations with CUDA.
It would be good to look at what your high priority filters are. I expect that writing them would be fairly easy in VTK-m. Writing new algorithms in VTK-m is done by writing templated C++ code so that shouldn’t be a major obstacle. VTK-m provides abstractions around data transfer and the differences between the different backends so the developer only has to learn a minimal amount of information such as the concept of disjoint memory spaces.
TBB/OpenMP is nice and we experienced that it can significantly improve performance compared to trivial multithreading, but it is not a game changer. In contrast, completely offloading critical time-consuming processing and rendering from the CPU to GPU would have huge impact.
We would like to have a solution that works well on most consumer laptops, so Cuda is not a very good option. OpenCL is at least not dependent on NVidia. GLSL works universally.
Right now, the two most critical filters are surface smoothing (vtkWindowedSincPolyDataFilter) and surface to image conversion (similar to vtkPolyDataToImageStencil but with fractional output).
Do you have GSL implementations of these filters? I am interested in the approach of using GLSL for some filtering operations. We are using VTK-m quite a bit too, but keeping more GPU resident without ever copying back has a number of advantages. It doesn’t feel like a general filter, but more of an end of pipeline operation before anything is rendered - perhaps not as general as some of what VTK/VTK-m filters try to do.
My understanding is that soon VTK-m, too, will be able do this. The main differentiator is that VTK-m is more general, better suited for complex algorithms, but it is larger and more complex than needed, if all you want to do is to run some simple processing implemented in GLSL.
Sorry for joining the conversation so late. I didn’t know this was going on and Andras just told me about it.
@Sunderlandkyl, this is really exciting work! I have wanted something like this for a while. The main reason why it is important is for interactive rendering and in particular volume rendering. For regular image processing tasks, users can often tolerate to wait a second or two. For volume rendering, many advanced illumination techniques rely on the ability to preprocess certain information over the whole volume and at interactive rates. For example, most recent volume self-shadowing techniques need to pre-integrate light attenuation every time the position of the light source or the transfer function change. There are many more application.
VTK-m looks nice, but I think most medical imaging projects such as Slicer are not willing to pay the price of such a heavy dependency to obtain advanced rendering, so it makes a lot of sense to integrate your work in VTK itself. Please let me know if you are still considering integrating this work in VTK. I could help with making sure the GPU volume rendering classes supports it.
If there is no interest in having this in VTK yet then we can integrate it into vtkAddon instead (a standalone library that adds a few general features to VTK). This way these GPU filters can be easily made available for Slicer and other projects, without modify anything in VTK.
It could be useful to have it there. The problem with this approach is that it wouldn’t be possible to integrate these pipelines with VTK’s GPU volume mappers. Last time I checked, VTK mappers explicitly upload volumes to the GPU memory. The integration of GPU processing pipelines from an external library would require to at least introduce a level of abstraction between the mappers and the 3D textures in GPU memory.
Yes, we’ll need a small API to enable GPU volume mappers to use texture that is already in the GPU. We can prototype that in a VTK fork and get that integrated into VTK proper when it is ready.