This post presents a new vtkForEach filter. Included in Common/Execution model, this is a filter of a new kind, operating at the pipeline level. Its general purpose is to create a loop on a sub-pipeline part. It is heavily inspired by the ttkForEach filter.
⟶
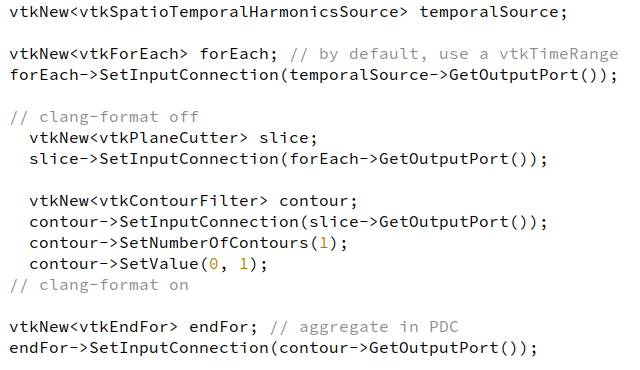

Left: example of a vtkForEach applied on a temporal data with an harmonic field evolving through time. On the sub pipeline, we extract a slice and a contour on the slice, leading to sinusoidal lines. The result is aggregated on a partitioned dataset shown on the right, colored by block id.
Overview
The goal of the vtkForEach is to provide the input for the sub-pipeline at each iteration. Doing so requires defining a loop criterion on the input data object, which is done by a dedicated class implementing the vtkExecutionRange interface. For example, we provide the vtkTimeRange, which loops over the discrete time steps of the input data object.
On the other side of the pipeline, the vtkEndFor receives the result of each sub-pipeline execution and uses a strategy following the vtkExecutionAggregator interface to reduce / aggregate all these data objects. For now, the vtkAggregateToPartitionedDataSetCollection is provided, which inserts each sub-pipeline results in a partition of a vtkPartitionedDataSetCollection.
Once the result has been processed, the vtkEndFor is in charge of telling the VTK pipeline that a new REQUEST_UPDATE_EXTENT / REQUEST_DATA pass is needed, using the vtkStreamingDemandDrivePipeline::CONTINUE_EXECUTING() key, until the vtkForEach filter indicates the end of the iterations.
In some way, this duo of filters can be seen as an externalization of the CONTINUE_EXECUTING mechanism. They make it easy to apply this key to filters that do not support it natively or to forge specific sub-pipeline to loops on. With some quick developments, it is even possible to range or aggregate data in custom ways, simply in implementing one of the two following interfaces:
vtkExecutionRange
Interface description:
An execution range is similar to a vtkAlgorithm, receiving a data object with associated pipeline information and providing a new object with new information. For this reason, the interface is a subset of the vtkAlgorithm one, containing the four Request* methods, connected to the corresponding pipeline passes received by the vtkForEach. A minor distinction is the addition of the iteration input parameter in the RequestUpdateExtent() and RequestData(), used to extract the right subpart of the input. For example, vtkTimeRange overrides the RequestUpdateExtent() method to set the UPDATE_TIME_STEP() key to the current iteration, in order to loop over time.
Ideas:
Some other execution range that could be implemented:
- Range over blocks of a composite data set
- Range over rows of a table
- Range over points / cell attributes
- Repeat N times (for benchmarks ?)
- …
vtkExecutionAggregator
Interface description:
An execution aggregator has two main methods. The first one is Aggregate(vtkDataObject* input) which is called at the end of each sub-pipeline execution, with the corresponding data object. In the existing vtkAggregateToPartitionedDataSetCollection, this method appends the input in an internal vtkPartitionedDataSetCollection. The second method is GetOutputDataObject() which allows retrieval of the results after all the iterations are done. If a reduction operation is done, it should be implemented here.
Ideas:
Some other aggregation strategies could be implemented:
- Appends all dataset into an unstructured mesh
- Resample all dataset into an image data
- Discard aggregator (do nothing, just used to do clever stuff in the loop)
- With a few changes, generate a temporal data object
- …
If you feel like implementing a new range or aggregator, we would be glad to help you do so!
Thanks @JonasLukasczyk for the initial work ![]()