I am a student. I am currently working on a project, where I have to generate a large cube composed of small cubes. For this, I generated csv files for vertices, edges, faces and also tetrahedra. Then in VTK I create a vtkUnstructuredGrid where I put all my vertices/edges/faces/tetrahedra (in fact each cube is actually a set of tetrahedra).
However, if this loading works well for a 10x10x10 cube, it does not work for a 100x100x100 cube. Indeed, my program is killed because of an out of memory at 90% of the edges loading. Knowing that for 100x100x100 I have to create about 6 millions edges.
Not being a great expert of vtk, I wanted to know if it was really possible to load such volume with vtk ? My final goal is to be able to visualize this with Paraview. Currently I save my vtkUnstructuredGrid in vtu file.
If it is normally possible to build such a volume, would you have some tracks to explore that could help me to solve my problem?
Thanks for your attention,
I hope to have been clear enough.
If you work with a structure grid of cubes (or rectangular prisms) then you can store them in a vtkImageData object and you can process and visualize it very efficiently. A 100x100x100 volume is considered very small and even a very old computer with a few GB of RAM can easily handle it.
Thank you very much for your answer. Indeed, I suspected that others have much greater needs than we do. I’m going to look at the documentation to see what I can do with these vtkImageData.
Even with double-precision values, it seems that your unstructured grid should only be a few hundred megabytes, which should be easy for VTK to handle as long as VTK was built for a 64bit architecture. Are you sure that you aren’t adding redundant points to the grid when you are building it? What’s the size of the .vtu file itself?
To give you a little more clue, here is my code that I restricted only to the construction of the points and lines so as not to overwhelm you. I’ve put all the steps in the code that I did to provide more context but in reality the “out of memory” happens on the seventh line of code where I create the “lines_weight” variable. I thought at first that creating millions of “pd.Series” might be a key factor. However, I tried just “vtk_cells.InsertNextCell(build_line(x))” (as for the points just above) and it always triggers the “out of memory”.
So to answer your questions. It seems to me that I don’t add the same points several times since I go through an “apply”. Also, I can’t tell you the size of the vtu since the program crashes (at line 7) before I can create it.
I hope to have answered and given enough indication.
Thank you for your attention.
def build_line(points):
line = vtk.vtkLine()
line.GetPointIds().SetId(0, int(points[0]))
line.GetPointIds().SetId(1, int(points[1]))
return line
def get_vtypes(weights, types):
vtypes = vtk.vtkUnsignedCharArray()
vtypes.SetNumberOfComponents(1)
nb_cells = sum([df.shape[0] for df in weights])
vtypes.SetNumberOfTuples(nb_cells)
for i in range(len(weights)):
df = weights[i]
tpe = types[i]
df.apply(lambda x: vtypes.SetTuple1(int(x[0]), tpe), axis = 1)
return vtypes
def build_point_weights(vtk_ungrid, points):
pointWeights = vtk.vtkDoubleArray()
pointWeights.SetName("PointWeight")
pointWeights.SetNumberOfComponents(1)
pointWeights.SetNumberOfTuples(vtk_ungrid.GetNumberOfPoints())
points.progress_apply(lambda x: pointWeights.SetTuple1(int(x[0]), x[4]), axis = 1)
return pointWeights
def build_weights(vtk_ungrid, cells, name):
cellWeights = vtk.vtkDoubleArray()
cellWeights.SetName(name)
cellWeights.SetNumberOfComponents(1)
cellWeights.SetNumberOfTuples(vtk_ungrid.GetNumberOfCells())
cells.progress_apply(lambda x: cellWeights.SetTuple1(int(x[0]), x[1]), axis = 1)
return cellWeights
# get vertices and edges dataframes
points = pd.read_csv(vertices_path)
edges = pd.read_csv(edges_path)
# setting vtk objects
vtk_ungrid = vtk.vtkUnstructuredGrid()
vtk_pts = vtk.vtkPoints()
vtk_cells = vtk.vtkCellArray()
# insert vertex and edges in vtk arrays and returns the weight of each edge with id
points.apply(lambda x: vtk_pts.InsertPoint(int(x[0]), x[1], x[2], x[3]), axis = 1)
# ERROR : OUT OF MEMORY
lines_weight = lines.apply(lambda x: pd.Series({"ID": vtk_cells.InsertNextCell(build_line(x)), "Weight": x[2]}), axis = 1)
# associate lines with type vtk.VTK_LINE for SetCells
vtypes = get_vtypes(weights=[lines_weight], types=[vtk.VTK_LINE])
# following code is just here to bring some context
# I accept your comments if you have any that do not
# concern my problem. It can always be instructive.
vtk_ungrid.SetPoints(vtk_pts)
vtk_ungrid.SetCells(vtypes, vtk_cells)
lines_weight = lines_weight.set_index("ID").reindex(range(vtk_ungrid.GetNumberOfCells()), fill_value=float("nan")).reset_index()
vtk_pts_weight = build_point_weights(vtk_ungrid, points)
vtk_ungrid.GetPointData().SetScalars(vtk_pts_weight)
vtk_ungrid.GetPointData().SetActiveScalars("PointWeight")
vtk_lines_weight = build_weights(vtk_ungrid, lines_weight, "LineWeight")
vtk_ungrid.GetCellData().AddArray(vtk_lines_weight)
writer = vtk.vtkXMLUnstructuredGridWriter()
writer.SetFileName('format/vtp_vtu_files/model.vtu')
writer.SetInputData(vtk_ungrid)
writer.Write()
The lines_weight in this code is a list of dicts, one dict per line? I suspect that it’s taking up much more memory than vtk_cells, since a vtkCellArray requires only 24 bytes per line. The memory footprint of a dict, even if empty, is 10 times as much:
>>> import sys
>>> sys.getsizeof(dict())
280
A simple check is to remove the vtkCellArray from that line of code and see if you still run out of memory. For example,
Ah, I misunderstood that. Can you tell me how many lines there are in each of your .csv files? That would allow me to compute exactly how much memory the vtkUnstructuredGrid would require.
The vtkCellArray AllocateEstimate method might also be of use for memory management:
AllocateEstimate(self, numCells:int, maxCellSize:int) -> bool
C++: bool AllocateEstimate(vtkIdType numCells, vtkIdType maxCellSize)
Pre-allocate memory in internal data structures. Does not change the
number of cells, only the array capacities. Existing data is NOT preserved.
@param numCells The number of expected cells in the dataset.
@param maxCellSize The number of points per cell to allocate memory for.
@return True if allocation succeeds.
That’s exactly the point. All the edges, faces, cells are completely unnecessary, because your data is a “large cube composed of small cubes”. Assuming all the small cubes have the same size and located at grid points of a regular grid, you no longer need to specify edges, faces, and cells anymore. All you need to store is the grid origin, spacing, axis direction, and value of each cube (empty/non-empty; or a scalar value). In most cases, processing, visualization, storage needs of such a regular structure is magnitudes easier/faster/smaller than of an unstructured grid.
pd.Series don’t seem to be as big as dictionaries but that doesn’t change much I guess. Anyway, indeed, replacing with your line I get the same result. So I tried with tuples that I add in a list instead of pd.Series but it doesn’t change much. However, it gives me some clues even if I was sure I had done the test a few months ago and concluded that vtk was taking too many places.
Oops, sorry I misunderstood. Here is the number of lines in my files:
number of vertices : 1 030 301
number of edges : 6 090 300
number of faces : 6 060 000
Is this function suitable for python since memory management is usually done by the language?
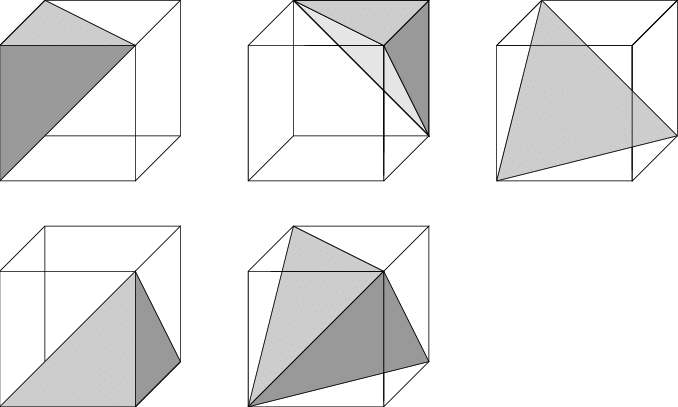
Excuse me, my first explanation was not very precise. The cubes that make up my final volume are of the form :
They need to be made with only simplices (vertices, edges, faces, tetrahedrons) because I want to access the value of any weight in my volume whether it is on a vertex, an edge, a face or a tetrahedron.
Since your end goal is to get the data into VTK, using pandas to read data is a waste of memory. And creating new data frames as you go along just exacerbates the problem.
You can read the data into VTK with practically no overhead by using Python’s built-in ‘csv’ module. Just iterate over the lines of each csv file, and put the data directly into the VTK arrays. Don’t be shy about using a “for” loop to do this.
With these and their associated weights, it should be 450MB.
Regarding memory in VTK, all of VTK is written in C++ and does its own memory management. The fact that we use VTK through Python doesn’t change that. So AllocateEstimate() will work to pre-allocate the array, and is more efficient than continually re-allocating as the array is expanded. Also GetActualMemorySize() will let you know how much memory each array or data object is using.
Thanks for your help, I’ll try not to use pandas anymore. However, I find it odd that it has no trouble loading the vertices (20 seconds or so) but as soon as I try to add my edges even without using pd.Series it takes about 20 minutes before it kills the process. Anyway I will try to apply these few hints by playing with the data structures I use, using the csv module of python. I’ll also do the upstream allocation although it shouldn’t change much I guess. I will give feedback if I find a solution that works.