Hello,
The new points after splitting becoming NaNs is the expected behavior. By definition, interpolating, say, between 42 and NaN is an indefined operation, hence the result is NaN. Then you need to fill all the NaNs in a post-processing step like you said. In my project, I leave this decision to the user:
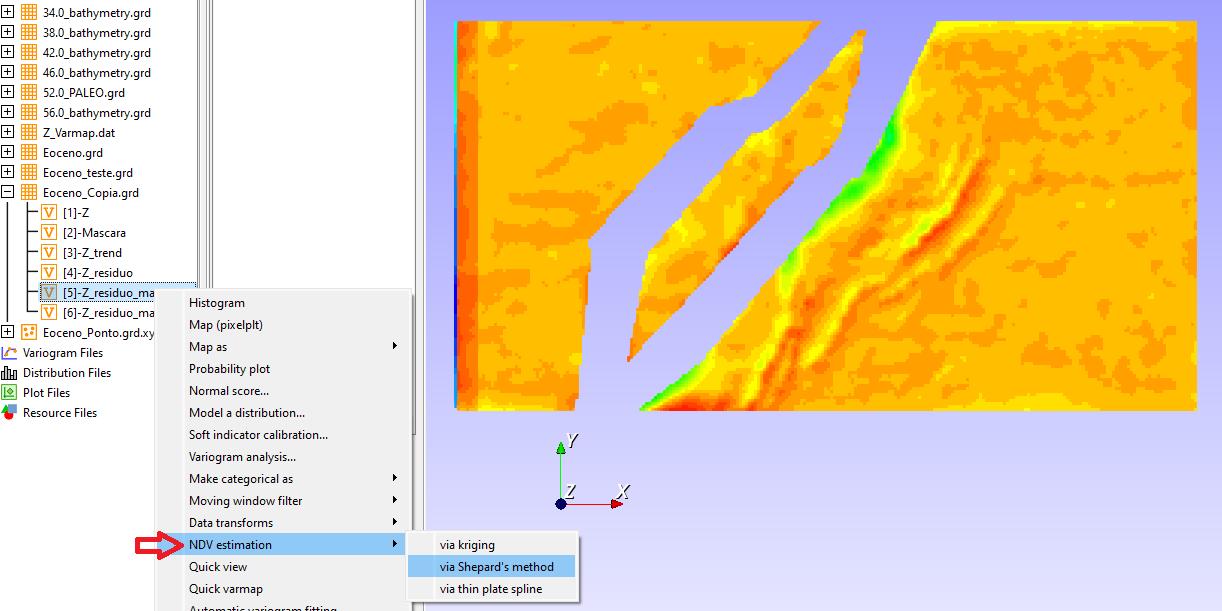
In the example above NDVs (non-data values) from the database are mapped to NaNs in VTK objects. So, whenever the user finds NaNs in the data after using some algorithm, one can interpolate them as a post-processing step.
best,
PC