Thanks for your answer.
Yes, we need “patches” and families as well and intend to keep them.
The main reason we need to update the reader is that we need the CGNS reader to match the “Conduit source”, which is the data coming from Catalyst2. Here is why: The typical way to use Catalyst2 is to load a simulation result file in ParaView (so using the CGNS reader in our case), and setup a post processing pipeline in a similar maner as you would when looking at a result file. That pipeline is then exported in the form of a paraview.simple python script and later executed by ParaView Catalyst when the simulation code runs on the cluster. When Catalyst2 run this pipeline, it replaces the disk reader by the so-called Conduit source, which is the simulation data in VTK data structures. The Conduit source produces PartitionedDataSetCollections, but currently the pipeline would be setup for data in multiblock datasets, since we set it up based on data coming from the CGNS reader.
Lets take an example based on the link provided above. Say I want to work on the inlet. I would typically use the ExtractBlock filter. There is two ways to use the ExtractBlock: A fetch by name and a fetch by path. If I use the fetch by path, it would look something like this:
ExtractBlock(“case.foam/boundary/inlet”, …), which is a path into the multi-block data structure. Because the Conduit source gives us a PartitionedDataSetCollection that may have different paths, this fetch by path might not apply and my pipeline would fail at run time.
Maybe @nicolas.vuaille has insights on aligning the disk readers and the Conduit source and can provide an idea I’m missing.
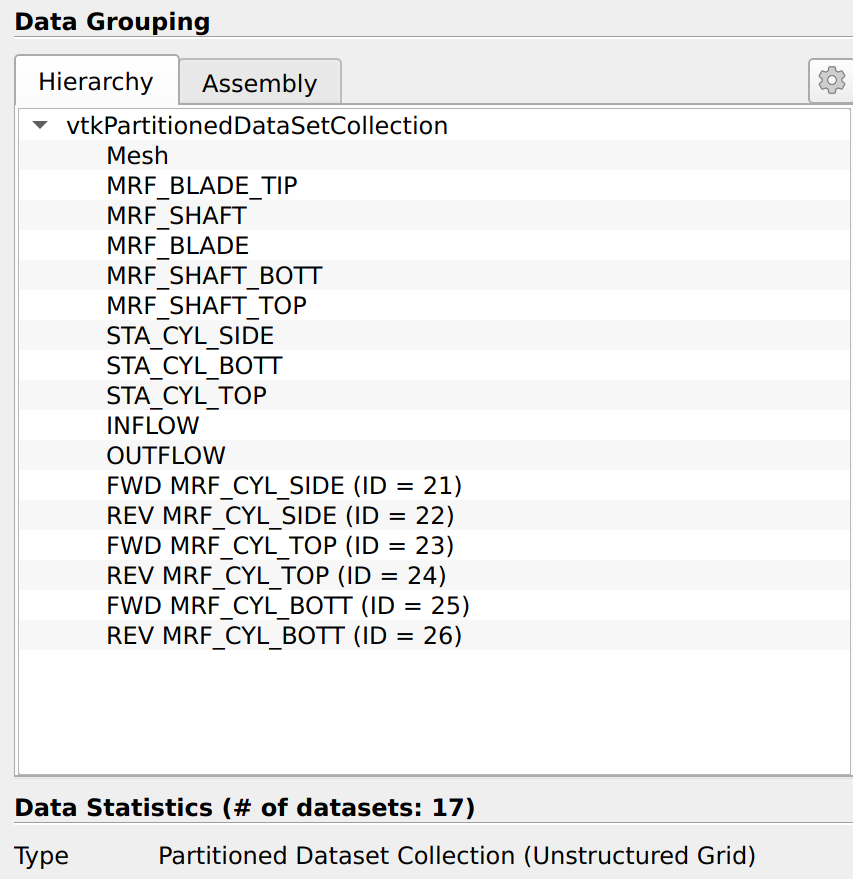
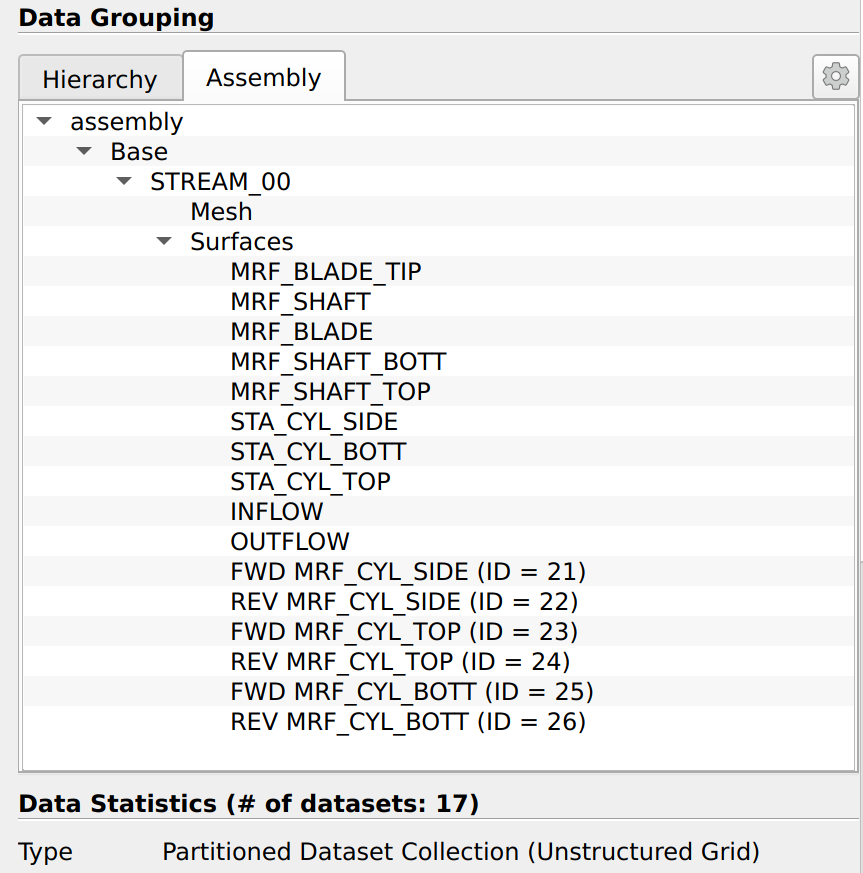
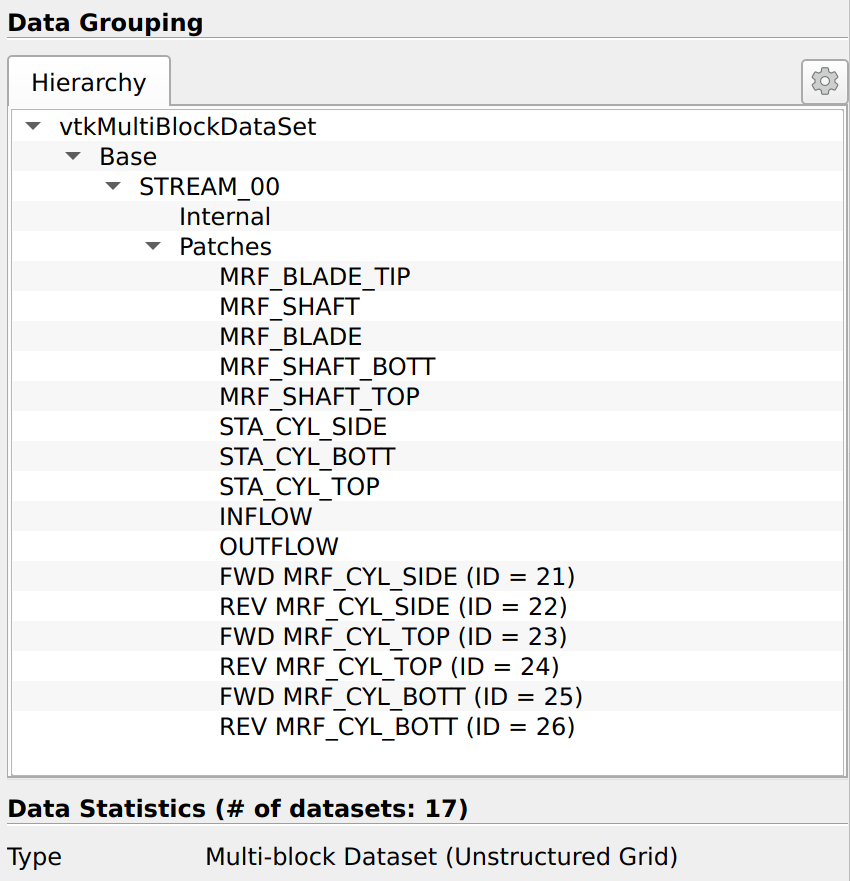
As a side note, I will mention another advantage of switching the CGNS reader to PartionedDataSetCollections. In this data structure, all the “blocks” are laid out flat next to each other, and an Assembly node is created for hierarchy. This assembly node is a tree of names that lets you organize the data. Here’s what it currently looks like in the CONVERGECFDCGNSReader:
As you can see, it matches the structure you would get with the CGNS reader:
So back to the potential advantage of PartionedDataSetCollections: Because the Assembly is simply a tree of names, it can easily be expanded. In particular, the tree of Family_t that is now possible in CGNS could be implemented in the assembly. I not sure we could do that cleanly with multiblock data sets.
@mwestphal , how do you see the depreciation working name wise? If the depreciated reader keeps the name vtkCGNSReader, what would you recommend calling the new one?