The ISO C++ mailings are the place to keep an eye on how C++ is progressing and whether anyone is working on such features: C++ Standards Committee Papers
At the moment the std thread backend has it’s own implementation of thread pool that’s seems to work ok, which could be replaced by a std thread pool if this feature appears in future C++ versions.
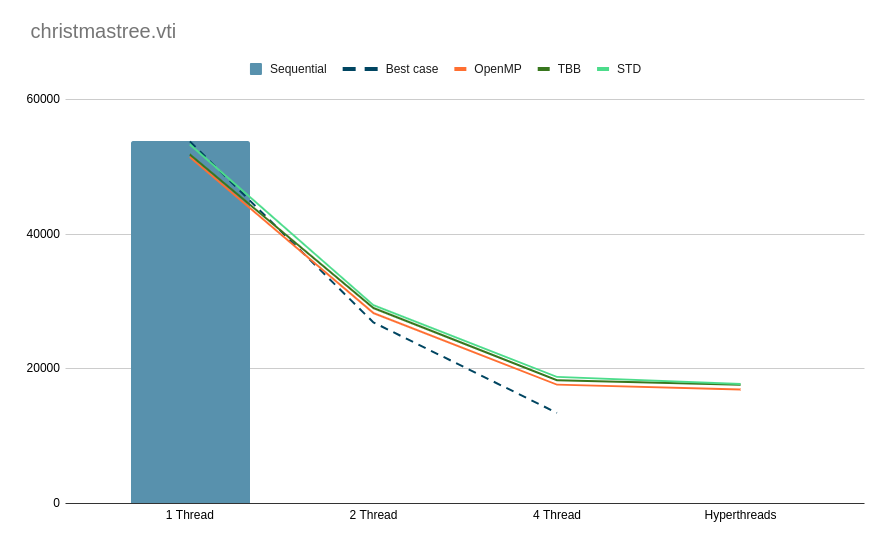
I did some tests to compare STD threads versus the other SMP backend and it seems to perform better than I expected, it is really close to TBB on the pipelines I tested.
Tests with 5 executions on each backend, the results are in ms, small pipeline with a vtkXMLImageDataReader, vtkFlyingEdges3D and vtkWindowedSincPolyDataFilter
A few years ago, me and Berk had a summer student work on implementing and benchmarking TBB vs. vtkMultiThreader for various filters in the VTK imaging pipeline.
On a 36-core Xeon machine, TBB was generally 20% to 30% faster. But on a 4-core i5, TBB was only 2% faster. We didn’t tease apart the effects of chip architecture vs. the number of cores, but the results suggested that large thread counts are where TBB really starts to shine.
I should add: in our benchmarks, the OpenMP backend of vtkSMPTools did not show any improvement over vtkMultiThreader.
For the benchmark you mention, was it memory intensive ? I did some bench too some time ago using 32 core (64 threads, two xeon) and TBB was more efficient when the memory was the limiting factor but I found no real distinction when the program was compute bound.
Another scenario where SMP backends with thread pools make a huge difference is when you create lots of threads (dozens or even hundreds of threads per second, because you work on small, quickly-changing data sets).
We found that frame rate of interactive volume slicing with rendered with NVidia GPU (with threaded optimization enabled) is limited to about 10-20 fps with vtkMultiThreader, but reaches 150-200fps with TBB. On some configuration the slowdown did not appear (e.g., Intel GPUs), and we could improve the performance by carefully tuning the number of threads in various filters in the pipeline.
However, manual tuning was impossible to do in our application (3D Slicer) because there are lots of different pipelines depending on what the user chooses to do. With TBB we just did not need to do any tuning, the performance was always reasonable and predictable: there were no unexpected performance inversions, such as slower updates with more threads, or slower rendering with higher-end graphics card.
Well, TBB showed the greatest speedup over MultiThreader for vtkImageCast (which is almost definitely memory-bound). I doubt memory vs. CPU was the only issue, but for our vtkImageCast test, TBB outperformed MultiThreader by around 50% for 36 cores but by only 2% for 4 cores. No hyper-threading in either test.