There are two new examples on the VTK Examples site. These were inspired by a comment in Easy Data Conversion to VTK with Python, namely: "Otherwise, for each of these different cases, there is a good chance that the Python ecosystem already provides an adequate tool to do the hard work.".
Accordingly, these examples will demonstrate how to use pandas to read and edit the CSV input file before passing it to the VTK system.
For the data, I have selected a CSV file LakeGininderra.csv of a walk around Lake Gininderra and also provided a kml file LakeGininderra.kmz that you can import into Google Earth.
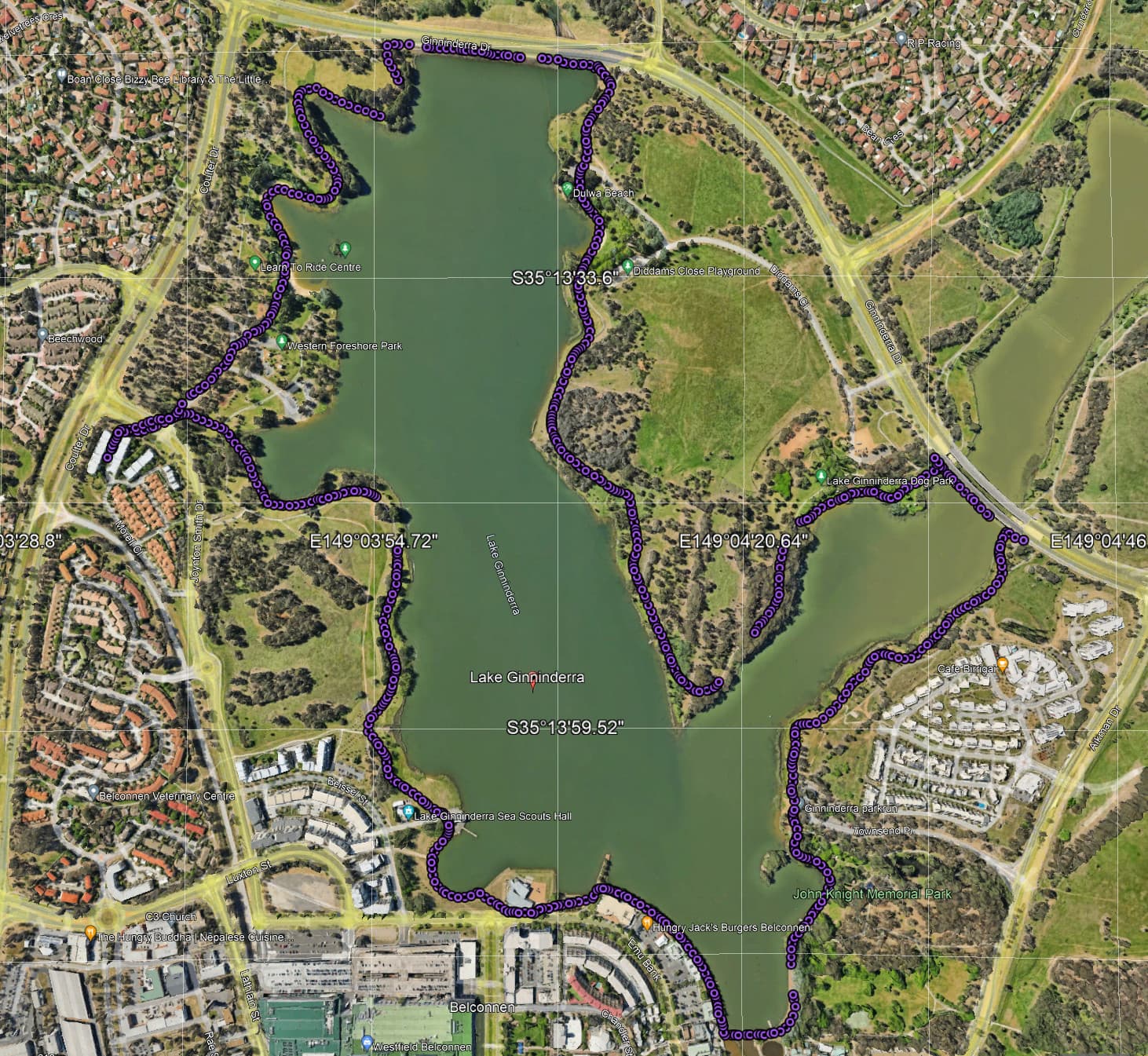
The CSV file has been edited to remove points that are close to each other. It has 759 rows and 21 columns of data. There are two speed columns, the first one is from the original data and the second is the calculated speeds from the edited data. Importantly, pandas will happily load both columns automatically renaming the second one from Speed(m/s) to Speed(m/s).1.
For these examples, we are really only interested in one of (Geographic, ECEF, UTM) coordinates along with elevation. Thus we just need three or four columns out of 21 in each case.
The first example, CSVReadEdit performs these operations:
CSV->pandas(read/edit/select)->numpy->numpy_to_vtk->vtkPolyData
In this example note how easy it is the get the three-dimensional coordinates using numpy.
The second example, CSVReadEdit1 performs these operations:
CSV->pandas(read/edit/select)->CSV->vtkDelimitedTextReader->vtkPolyData
By going down this route we don’t overload the delimited text reader with the effort of processing any unneeded columns of data.
In both examples you can plot UTM coordinates -u, ECEF coordinates -e and write out a CSV file of geographic coordinates -g. Note that the file of geographic coordinates can be directly imported into Google Earth. Additionally, to save a CVS file of the ECEF or UTM coordinates use -c and, to save a VTP file, use -v. The VTP file can be loaded into ParaView.
Feel free to experiment with the pandas DataFrame:
- You may like to change the Elevation from metres to feet or the speed in
Speed(m/s).1from m/s to furlongs/fortnight. - Select only rows where the speed exceeds a certain value. To extend this … you may then like to recalculate distances between the selected points again.
- Select only rows where distance from the previous point is greater than say 12m. Once again speeds would need to be recalculated.
There are very many operations you can do on the DataFrame and a lot of them are the same as or similar to numpy. The other advantage of pandas is that it easily handles missing data. Look in the DataFrame to see where there are nans.
Hopefully these examples will give you some ideas whenever tabular data is involved. Pandas can efficiently handle huge amounts of data and is very closely integrated with numpy. So it is a good adjunct for VTK whenever tabular data is involved
Have fun.