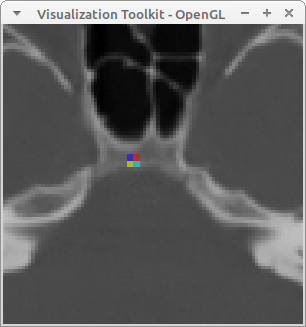
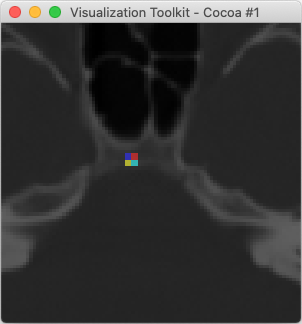
Here is an example of overlaying two images that are already in the same physical space but don’t have the same bounds or the same sampling. In this example, we set the OutputExtent of the overlay image to a cropped extent to avoid having vtkImageReslice produce a whole bunch of zeros for its background.
If the images are not in the same physical space, but there is a known transformation to go from the space of image A to the space of image B, then the math is different but the concepts are much the same.
You’ll have to excuse me for writing the example in Python.
"""
A simple example of overlaying two images.
The images must be in the same physical space, but can have different
position, size, and voxel spacing.
In this example, the Orientation of the images must be the identity matrix.
"""
import vtkmodules.all as vtk
import math
# for this example, any 256x256 image will do
brainfile = "ExternalData/Testing/Data/fullhead15.png"
def commonInformation(imageA, imageB):
"""Compute a new image geometry that encompasses two images.
The first image will be used for the voxel spacing.
Warning: if the two images are far apart, the resulting dimensions
might be very large.
"""
# compute common bounds
bounds = [0.0]*6
imageA.GetBounds(bounds)
boundsB = imageB.GetBounds()
for i in range(3):
bounds[2*i] = min(bounds[2*i], boundsB[2*i])
bounds[2*i + 1] = max(bounds[2*i + 1], boundsB[2*i + 1])
# always use spacing from the primary image
spacing = list(imageA.GetSpacing())
# compute the new origin and dimensions: ensure that the new voxels are
# sited at the same points as the primary image so that the primary image
# will not have to be interpolated
dimensions = [1]*3
origin = list(imageA.GetOrigin())
for i in range(3):
lb = bounds[2*i]
ub = bounds[2*i + 1]
# compute the number of voxels by which the origin will shift
offset = round((lb - origin[i])/spacing[i])
origin[i] += spacing[i]*offset
# use upper bound to get the dimension along this axis
dimensions[i] = round((ub - origin[i])/spacing[i]) + 1
return origin, spacing, dimensions
def setOutputInformation(reslice, origin, spacing, dimensions):
"""Given a vtkImageReslice filter, set the Output information.
"""
reslice.SetOutputOrigin(origin)
reslice.SetOutputSpacing(spacing)
reslice.SetOutputExtent(0, dimensions[0] - 1,
0, dimensions[1] - 1,
0, dimensions[2] - 1)
def setOutputInformationWithCropping(reslice, origin, spacing, dimensions):
"""Given a vtkImageReslice filter, set the Output information.
The output is cropped to the input bounds to increase efficiency.
When blending, this can be applied to the overlay image, but not to
the base image.
"""
# the input data must be updated before this!
inputImage = reslice.GetInput()
bounds = inputImage.GetBounds()
extent = [0]*6
extentF = [0.0]*6
for i in range(3):
# crop to bounds
extent[2*i] = int(round((bounds[2*i] - origin[i])/spacing[i]))
extent[2*i + 1] = int(round((bounds[2*i + 1] - origin[i])/spacing[i]))
# add a border to avoid boundary issues
extent[2*i] -= 1
extent[2*i + 1] += 1
# clamp to dimensions
extent[2*i] = max(extent[2*i], 0)
extent[2*i + 1] = min(extent[2*i + 1], dimensions[i] - 1)
reslice.SetOutputOrigin(origin)
reslice.SetOutputSpacing(spacing)
reslice.SetOutputExtent(extent)
# the first image is a brain
reader = vtk.vtkPNGReader()
reader.SetFileName(brainfile)
reader.SetDataOrigin(0.0, 0.0, 0.0)
reader.SetDataSpacing(1.0, 1.0, 1.0)
reader.Update()
# use the full scalar range of first image
imageA = reader.GetOutput()
rangeA = imageA.GetScalarRange()
tableA = vtk.vtkScalarsToColors()
tableA.SetRange(rangeA)
# the second image is a small activation area
imageB = vtk.vtkImageData()
imageB.SetDimensions(2, 2, 1)
imageB.SetOrigin(120.25, 130.25, 0.0)
imageB.SetSpacing(2.0, 2.0, 2.0)
imageB.AllocateScalars(vtk.VTK_UNSIGNED_CHAR, 1)
imageB.SetScalarComponentFromDouble(0, 0, 0, 0, 63)
imageB.SetScalarComponentFromDouble(0, 1, 0, 0, 127)
imageB.SetScalarComponentFromDouble(1, 0, 0, 0, 191)
imageB.SetScalarComponentFromDouble(0, 1, 0, 0, 255)
# use a color LUT for second image
tableB = vtk.vtkLookupTable()
tableB.Build()
tableB.SetRange(0, 255)
# compute the common grid for resampling the images
origin, spacing, dimensions = commonInformation(imageA, imageB)
# reslice first image to common space
resliceA = vtk.vtkImageResliceToColors()
resliceA.SetOutputFormatToRGB()
resliceA.SetLookupTable(tableA)
resliceA.SetInputData(imageA)
setOutputInformation(resliceA, origin, spacing, dimensions)
resliceA.Update()
# reslice second image to common space
resliceB = vtk.vtkImageResliceToColors()
resliceB.SetOutputFormatToRGBA() # RGBA for background transparency!
resliceB.SetLookupTable(tableB)
resliceB.SetInputData(imageB)
setOutputInformationWithCropping(resliceB, origin, spacing, dimensions)
resliceB.Update()
# blend and display the images
blend = vtk.vtkImageBlend()
blend.SetInputData(resliceA.GetOutput())
blend.AddInputData(resliceB.GetOutput())
blend.SetOpacity(1, 0.5)
blend.Update()
iren = vtk.vtkRenderWindowInteractor()
style = vtk.vtkInteractorStyleImage()
# use this for 3D images
#style.SetInteractionModeToImageSlicing()
iren.SetInteractorStyle(style)
win = vtk.vtkRenderWindow()
win.SetInteractor(iren)
ren = vtk.vtkRenderer()
win.AddRenderer(ren)
mapper = vtk.vtkImageSliceMapper()
mapper.SetInputData(blend.GetOutput())
blendExtent = blend.GetOutput().GetExtent()
mapper.SetSliceNumber(int((blendExtent[4] + blendExtent[5])/2.0))
actor = vtk.vtkImageSlice()
actor.SetMapper(mapper)
actor.GetProperty().SetInterpolationTypeToNearest()
ren.AddViewProp(actor)
win.Render()
ren.GetActiveCamera().Zoom(4.0)
iren.Start()
Output image: