Hello Group, I am having performance issues while extracting SAGGITAL/CORONAL planes using VTKImageReslice. Each call to VTKImageReslice->GetOutput() takes 5-7 ms.
The volume used has the following properties:
Dimensions: 512x512x297
Pixel spacing: 0.4x0.4x0.7
Scalar type: Unsigned Int16
Number of components: 1 (Monochrome).
System & Build environment:
Windows 7, 12GB RAM, i3 processor.
Visual studio 2013
VTK 7.1.1
WPF for UI
Are there any known considerations for making VTKImageReslice fast?
There are two common causes for vtkImageReslice to be slower than it should be:
Some people only need to extract a single slice from the volume, but write their pipeline such that the OutputExtent of vtkImageReslice is a 3D extent. Then, after vtkImageReslice has produced a full 3D volume, they display just one slice of that output volume. All the extra work of reslicing the full volume instead of just extracting one slice will cause the filter to take e.g. 100x longer than it should. I don’t know if this fits your situation, you would have to show me your code.
If you let the VTK pipeline automatically update filter or reader that precedes vtkImageReslice, instead of calling Update() manually on that read/filter, then a special feature of the pipeline called “streaming” can automatically be engaged. This can cause the upstream pipeline to be executed every time that vtkImageReslice itself is updated, resulting in a slowdown.
A further consideration is the way that the CPU cache handles different memory access patterns. This doesn’t impact performance as much as the two items described above, but if you benchmark sagittal and coronal separately it is normal to see that sagittal slicing is 2 or 3 times slower than coronal. You should check to see if this is the case with your code. Note that speed issues related to the cache are expected and there isn’t much to be done about them unless you want to do cache-specific profiling and optimization.
Finally, note that vtkImageReslice is multithreaded but it only uses the CPU, so it cannot be expected to come anywhere close to the performance of GPU interpolation. Actually, 5ms to extract a 512x297 sagittal slice from a 512x512x297 volume seems to be in the right ballpark for an i3 CPU.
I am also having the same problem, i need to make an average operation so to do it in 2d does not help in my case. Is there any other option to reslice a volume?
hello, thank you for your information.I have a similar question with vtkSplineDrivenImageSlicer.
Here is my code:
vtkNew appendThread;
appendThread->SetAppendAxis(2);
It takes me about twelve seconds to slice 500 sections.What I know is that vtkSplineDrivenImageSlicer uses vtkImageReslice.could you please tell how to speed it up?thank you!
You extract 500 slices, so the computation time should be around a few seconds. If you extract frames at higher-resolution or your computer is very slow then it may be normal that it takes 12 seconds.
I would not recommend using vtkSplineDrivenImageSlicer. Not because it is slow (it would be hard to make this faster without reducing the output resolution), but because all it does that it computes the reslicing parameters along a curve and puts the result in the image. This is not sufficient for any applications, which go beyond just straightening out an image.
Instead, what you need is a transform that you can use to straighten out either an image (using vtkImageReslice) or any other data types, such as surface meshes, curves, etc. (using vtkTransformPolyDataFilter). VTK transformation infrastructure is very smart, so it can dynamicallt invert the transformation for you, so for example, you can mark a point in the original volume and get the position in the straightened volume.
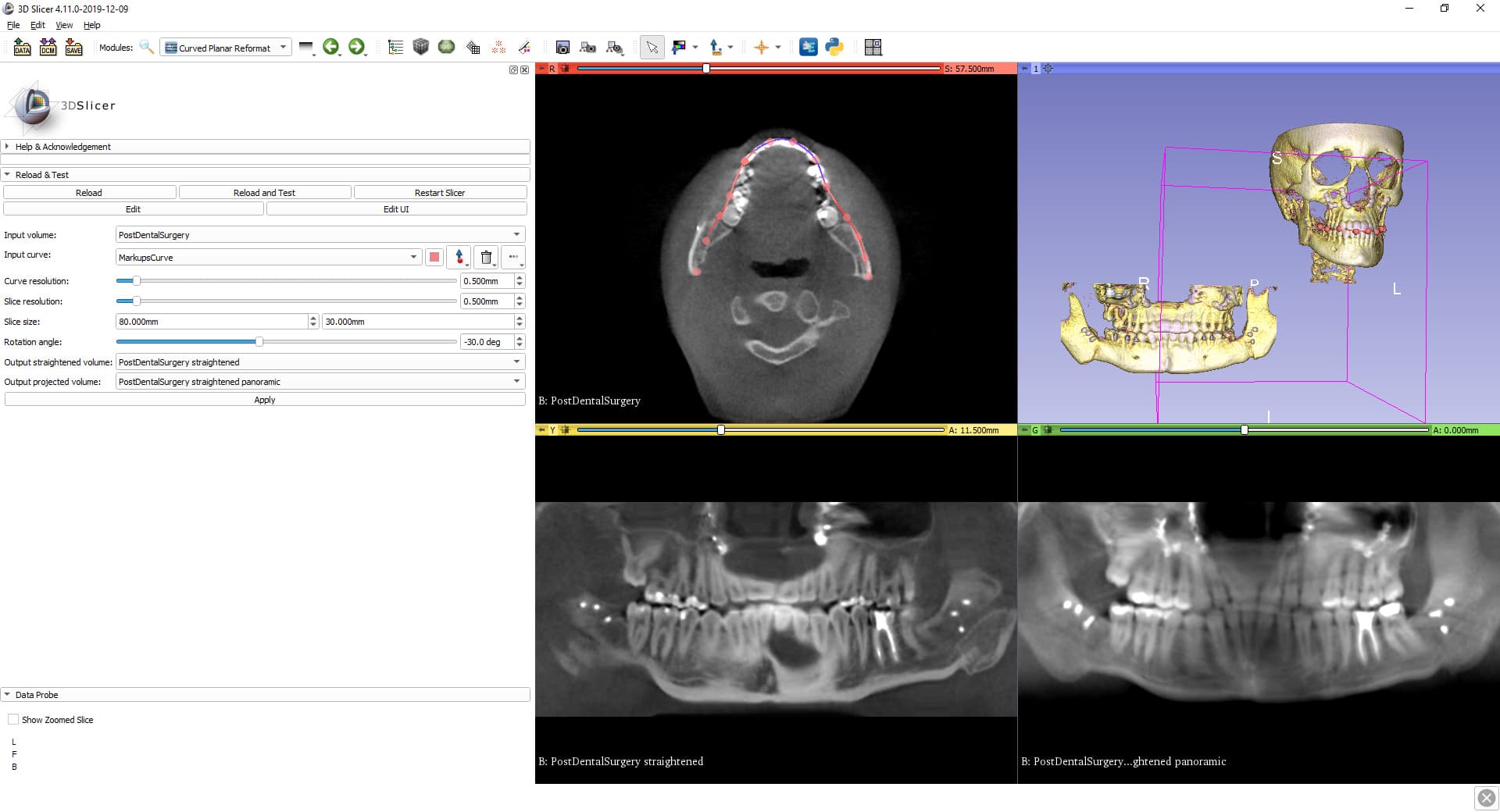
We have implemented this transform generation in the Curved Planar Reformat module in 3D Slicer’s Sandbox extension. You can find the full source code here, or you can just use the module with a convenient GUI (or from your Python scripts) within 3D Slicer. A short description/discussion of how the transform is generated is available here.